


从GPT1到GPT4的差异是什么,ChatGPT究竟改变了什么?

正如名称所示,GPT-4 是OpenAI设计的一系列 NLP 工具中的第四个。在其推出之前,该模型经过了多年的开发,经历了一个旅程,以达到我们今天在AI文本生成领域所知道的创新状态。本文将讨论GPT模型的发展和演变,即 GPT-1、GPT-2 和 GPT-3。
在 GPT 之前,NLP 模型通常需要大量的经过注释的数据来训练特定任务。这造成了一个重要的限制,因为准确训练模型所需的标记数据数量并不容易获得。NLP 模型局限于其训练内容,难以执行开箱即用的任务。
而据说 OpenAI 在创立之初时,所有人都有一个坚定的信念,那就是“数据量是走向 AGI 的最关键因素”。于是为了克服这些限制,OpenAI提出了一种生成式语言模型(GPT-1),使用未标记的数据进行构建,并允许用户微调语言模型,以便它可以执行下游任务,如分类、问题回答、情感分析等。这意味着模型输入(一个句子/一个问题),并尝试生成一个适当的响应,而用于训练模型的数据没有标记。
发展历程
GPT-1:不同关注点的起点
GPT-1 于 2018 年由 OpenAI 推出。在一个巨大的 BooksCorpus 数据集上进行训练,这个生成式语言模型能够学习大量的依赖关系,并获得对连续文本和长段落的广泛知识。在其架构方面,GPT-1 应用了 12 层解码器的转换器架构,并使用了自我关注机制进行训练。
由于其预训练,GPT-1 的一个显著成就是其在各种任务上的 zero-shot [相关解释] 性能。
在有监督学习的 12 个任务中,GPT-1 在 9 个任务上的表现超过了 state-of-the-art 的模型。但更重要的是,在没有见过数据的 zero-shot 任务中,GPT-1 的模型要比基于 LSTM 的模型稳定,且随着训练次数的增加,GPT-1 的性能也逐渐提升,表明 GPT-1 有非常强的泛化能力,能够用到和有监督任务无关的其它 NLP 任务中。
这种能力证明了生成式语言建模可以利用有效的预训练概念来推广模型。以其为基础的迁移学习使GPT成为一个执行自然语言处理任务的强大工具,只需要非常少的微调。
众所周知,泛化能力是 AGI 的最重要能力之一,而我认为这也是为什么 OpenAI 能够愿意持续投入时间和金钱坚定 GPT 技术路线的最重要原因之一。
GPT-2:足够好但还是略逊 BERT 一筹
2019 年末,OpenAI 开发了第二代 GPT,使用了更大的数据集并添加了额外的参数来构建更强大的语言模型。与 GPT-1 类似,GPT-2 利用 Transformer 模型的解码器。
GPT-2的一些重要进展是其模型架构和实现,它拥有 15 亿个参数,比 GPT-1(1.17亿个参数)大 10 倍,同时它的参数和数据比其前身 GPT-1 分别多出 10 倍。它是在多样化的数据集上进行训练的,使其在解决与翻译、摘要等相关的各种语言任务方面非常强大,仅使用原始文本作为输入,几乎不需要训练数据。
GPT-2在几个下游任务的数据集上的评估表明,它通过显著提高识别长距离依赖和预测句子准确性的方式优于其他模型。
然而,虽然相比 GPT1,GPT2 增大数据集获得了很不错的能力提升,但是却没有获得比小的多的 BERT 模型更多的提升,此时 OpenAI 只能在论文中主要探讨 GPT2 在不需要微调的情况下的 Zero-shot 能力。

横坐标是GPT-2模型的参数量,可以发现随着参数量的提升,模型在各种任务上的表现仍然可以提升
GPT-3:大力出奇迹
GPT-3 是迄今为止生成预训练模型系列的第三个版本。它是由OpenAI开发的大规模语言预测和生成模型,能够生成原始文本的长序列。
GPT-3 横空出世之时,GPT-3 马上成为了当下最强大的语言模型,仅仅需要 zero-shot 或者 few-shot,GPT-3 就可以在下游任务表现的非常好。除了几个常见的NLP任务,GPT-3还在很多非常困难的任务上也有惊艳的表现,撰写文本、浓缩信息、甚至扮演老师等等。
三个GPT模型之间的区别在于它们的大小。最初的 Transformer 模型约有 1.1 亿个参数。GPT-1 采用了这个大小,GPT-2 的参数数量增加到了 15 亿,而 GPT-3 的参数数量增加到了 1750 亿,成为最大的神经网络。

有意思的是,当时的 MIT Technology Review 评价道:
**OpenAI’s new language generator GPT-3 is shockingly good—and completely mindless**
很多人的评价也是如此,虽然 GPT-3 很惊艳,可以随时生成惊人的类似人类的文本,但是不会让我们更接近真正的智能。
GPT-3.5:加入人类反馈后的更好版本
为了放出可以给更多人使用的 GPT 产品,OpenAI 使用 GPT-3 预训练的语言模型作为起点, 做了更多的事情。
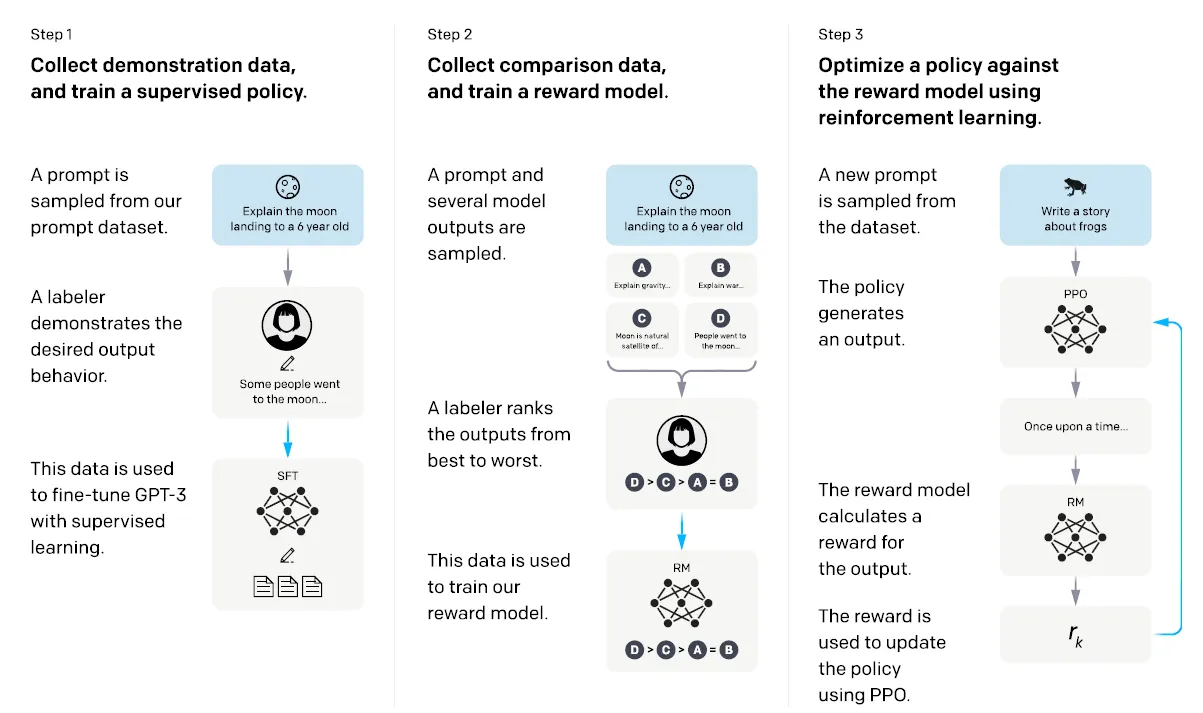
收集演示数据并训练有监督的策略。标签提供所需行为在输入提示分布上的演示。然后,使用有监督学习将预训练的 GPT-3 模型对此数据进行微调。
收集比较数据并训练奖励模型。收集了一个模型输出之间的比较数据集,其中标签指示他们更喜欢给定输入的哪个输出。然后训练一个奖励模型来预测人类首选的输出。
使用 PPO 优化策略以针对奖励模型。RM 的输出用作标量奖励。使用 PPO 算法微调有监督的策略以优化此奖励。
步骤2和3可以不断迭代;在当前最佳策略上收集更多比较数据,用于训练新的 RM。
GPT-4:AGI 曙光
OpenAI 于 2023年3月14日推出了 GPT-4。根据 OpenAI 的说法,GPT-4 在几个关键方面都比它的前任有所提高。
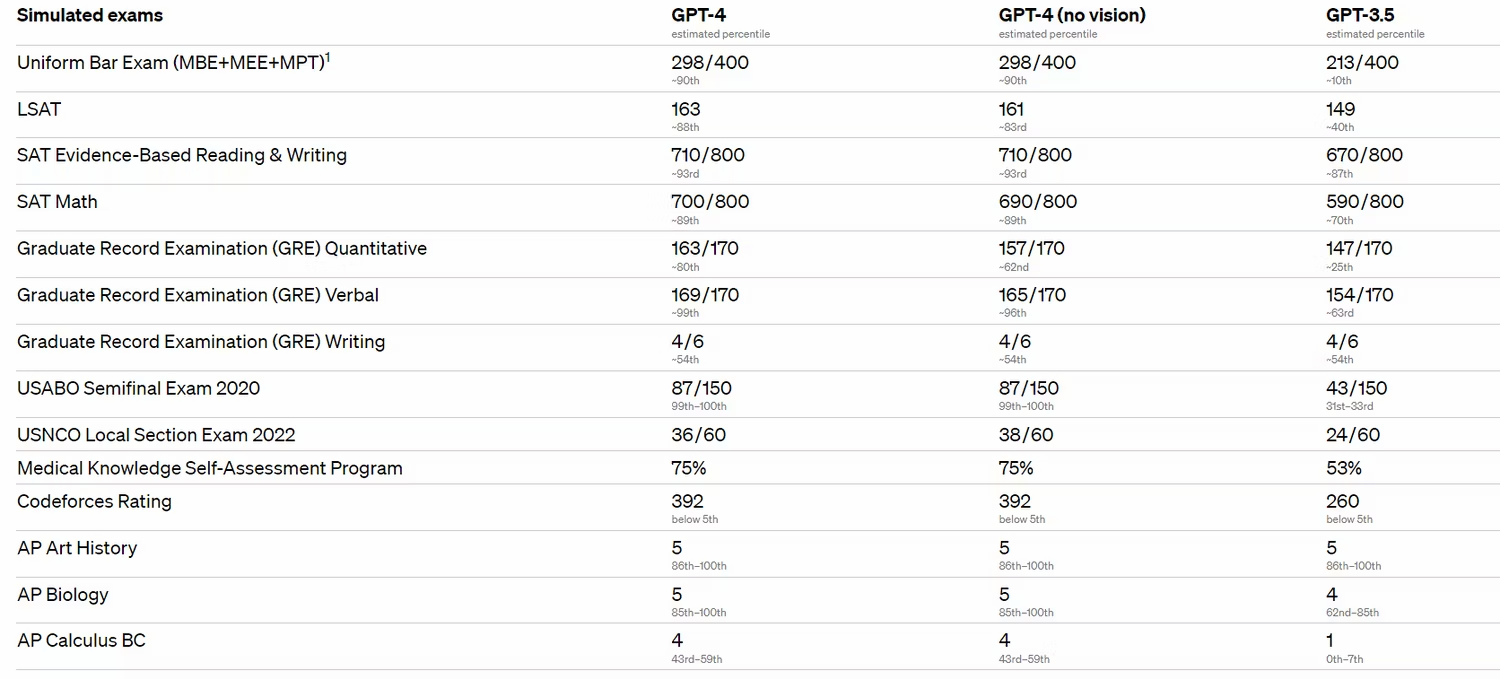
首先是能力提高:在 Uniform Bar Exam (美国律师从业考试)考试中得分比 GPT-3.5 在 ChatGPT 中高得多(它在测试中得分位居前 10%,而 GPT-3.5 在测试中得分位居后10%)。它也更具创造力,并且更加关注安全和防止信息误传。
其次,GPT-4 还可以使用图像作为输入信息,识别图片中的对象并进行分析。
在 GPT-4 模型释出后,掀起了非常大的反响,微软研究院的大佬们不仅亲自下场测评后给出评价:“GPT-4 是 AGI 的曙光”,首席研究员也发出宣言:“全面转向 AGI 研究”。
