不知不觉,距 GPT-4 首次公开问世,已经过去一个月了。在这段时间,有不少人拿到了 GPT-4 API 权限,开通了 ChatGPT Plus,提前体验了 GPT-4 的能力。这些人无一例外,都被 GPT-4 强大的逻辑分析、统筹规划能力深深折服。无论是论文创作、编写代码、还是数据分析,GPT-4 都给出了令人惊艳的表现。不过,大家可别忘了,GPT-4 作为一个多模态大语言模型,它不仅能生成文字内容,还能理解图像输入内容,让用户直接与图片进行对话。一个月前,OpenAI 向外界演示了 GPT-4 如何通过手绘草图,直接生不仅如此,它还能 get 到图像里面的笑点,识别数学题目并依次给出解答步骤。我始终觉得,图像对话才是 GPT-4 真正令人心神向往之处。但可惜的是,这个功能至今仍没有对外开放。除了 Be My Eyes、可汗学院等少数几家与 OpenAI 有建立合作的企业,大部分人还是只能体验 GPT-4 的文本对话能力。原本我以为只能苦等 OpenAI 发布更新,才能体验上这个功能,没成想今天让我找到了这么一个项目。该项目名为 MiniGPT-4,是来自阿卜杜拉国王科技大学的几位博士做的。它能提供类似 GPT-4 的图像理解与对话能力,让你先人一步感受到图像对话的强大之处。GitHub:https://github.com/Vision-CAIR/MiniGPT-4在线体验:https://minigpt-4.github.io/项目作者认为,GPT-4 所实现的多模态能力,在以前的视觉 - 语言模型中很少见,因此认为,GPT-4 先进的多模态生成能力,主要原因在于利用了更先进的大型语言模型。为了验证这一想法,团队成员将一个冻结的视觉编码器与一个冻结的 Vicuna 进行对齐,造出了 MiniGPT-4。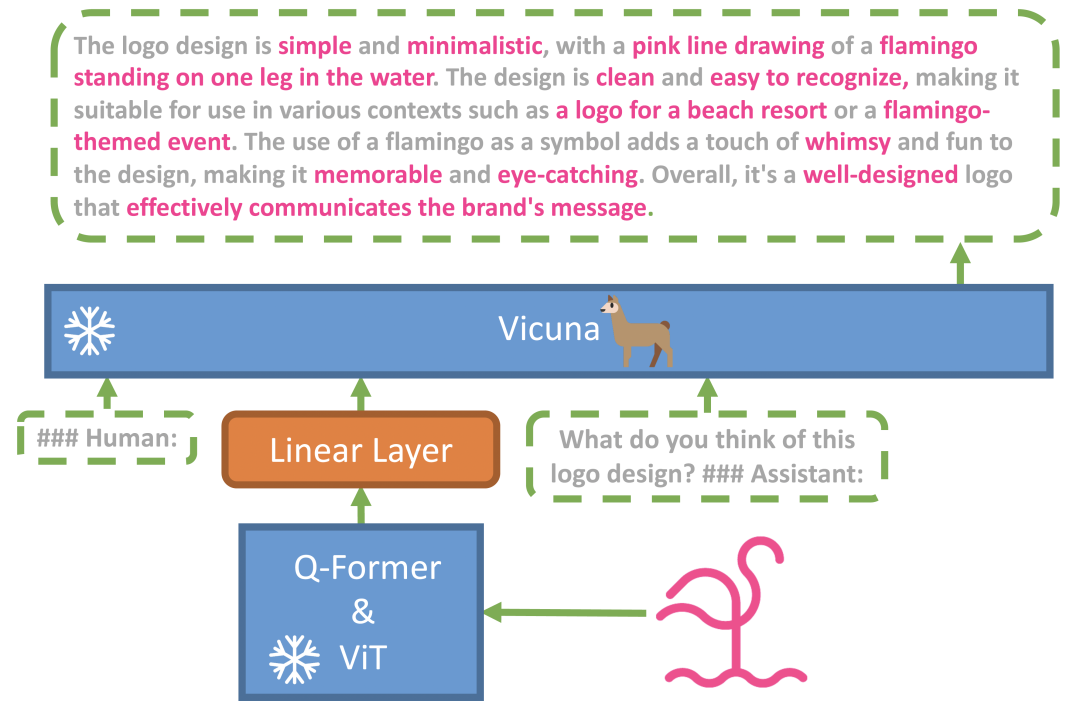
在研究中,他们发现 MiniGPT-4 具有许多类似于 GPT-4 的能力,如详细的图像描述生成、从手写草稿创建网站等。不仅如此,他们还在研究中还收获了意想不到的惊喜,除了能实现上述功能之外,MiniGPT-4 还能根据图像创作故事和诗歌,为图像中显示的问题提供解决方案,教用户如何根据食物照片做饭等。根据实验结果表明,GPT-4 这些先进的能力,理论上可以归因于它使用了更先进的大语言模型。也就是说,未来在图像、声音、视频等领域,基于这些大语言模型所造出来的应用,其实际效果都不会太差。
这个项目证实了大语言模型在图像领域的可行性,接下来应该会有不少开发者入场,将 GPT-4 的能力进一步往音频、视频等领域延伸,进而让我们得以看到更多有趣、令人惊艳的 AI 应用。
本篇文章来源于微信公众号: GitHubDaily




